Please see the PubMed reference below for background information about this phenotype & algorithm (a copy also attached).
This is based on a phenotype algorithm that was already published a couple years ago by NU, and has been further refined in collaboration with Geisinger whom also has expertise in this area. In addition, given that ICD-10 codes just started being used w/in the last year, we have updated the algorithm w/ those codes & have re-run & re-validated it at both NU & Geisinger. Finally, we have added logic to sub-divide the CRS cases into those w/ and w/o nasal polyps, which is simply a division based on the coded data already used for the CRS phenotype.
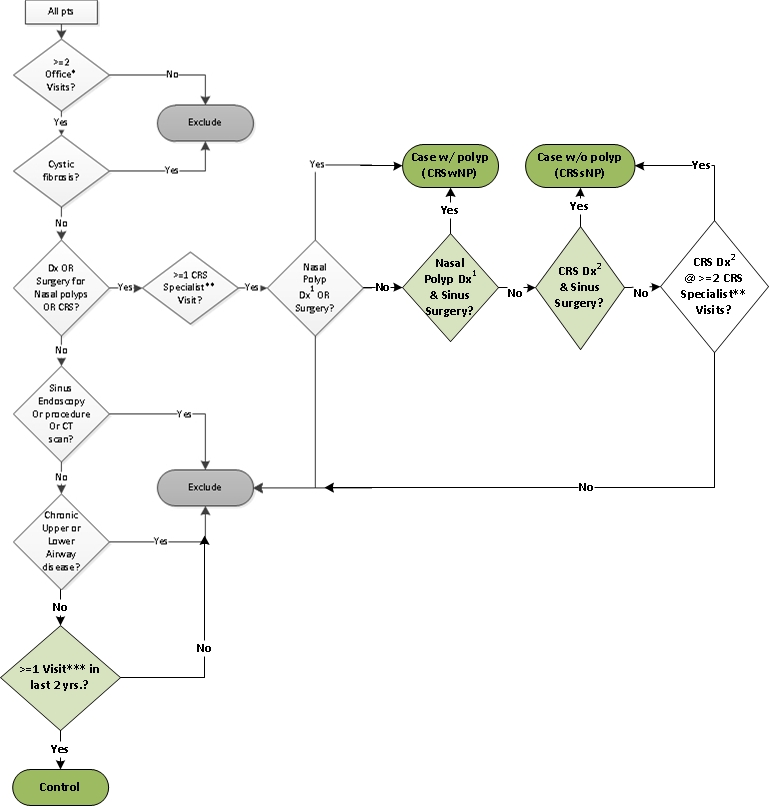
The final version of the algorithm for other sites to run, is almost the same as the published version (a copy also attached -the algorithm to use is depicted in Figure 2 and is described in the footnotes of that figure and in the text of the manuscript) w/ 3 additions and 1 correction as follows: an updated flowchart is attached which depicts these changes:
1) ICD-10 codes (in attached Excel file of diagnosis and procedure codes)
2) dividing up cases into those with vs. without nasal polyps for sub-phenotype analysis
3) Controls must have been seen in person in the last 2 years (in an inpatient, outpatient, or ED encounter - the same types of encounters that all diagnoses must originate as in the published algorithm).
Correction: ICD-9 codes for cystic fibrosis corrected (2 removed: 277.9 and V13.8x)
*** If you use SNOMED codes, we have limited ablility to test, but can add SNOMED codes for those sites that use it, please just let us know.
To make it easy to implement, there is a KNIME workflow attached, created by Geisinger & tested at both sites, that any site can easily use. Instructions are in the workflow itself. KNIME is freely avail. s/w that can be downloaded from knime.org to run on any platform, and can connect to any DB or file type. The workflow simply reads in your encounter diagnoses and procedure data in the specified format in the workflow, and then executes all the phenotype logic for you, and outputs the data in the data dictionary format.
Please do NOT use the current PhEMA version of this algorithm is in progress, it is a draft -- the PhEMA software needs an upgrade for it to accomodate "seen by specialist," which won't happen in time for this to be run, so we won't be using it for this phenotype except for testing by NU.
{kind=link}
Comments
Version 2.4 of workflow uploaded
Updated to fix bug that allowed subjects to be categorized as both case2.1 and case2.2. These are know mutually exclusive.
bug discovered in KNIME workflow on June 15, 2017 update
We discovered a bug in the KNIME workflow, we are fixing & testing it now, along w/ adding & testing SNOMED codes for those sites that use it. A new workflow will be posted shortly. If you already started using KNIME workflow versions 2.4 or earlier, do not worry, you will be able to copy & paste your queries & database connections into the new version 2.5, as the error is later in the workflow in the part that applies the algorithm logic to the data.
Jen & Ken
BMI in data dictionary
In the DD, there is no value specified to use when there is no BMI available for a subject, please advise.
Thanks,
Vivian
BMI in DD
the BMI field was giving another user a different error, so to accomodate everyone, I am uploading a new DD now w/ BMI as a simple decimal field, so simply leave blank if no BMI is available -- if there is not a BMI at the time of the data pull, please use median (of all available BMI over time) BMI if that is available.
Thanks, Jen
KNIME input specs
UW asked "Are there input data specifications available somewhere for the KNIME workflow?"
Yes, there are: The input data specifications are in the KNIME workflow itself as follows:
In the main workflow on the left there are 4 steps listed to implement the KNIME workflow.
When you begin steps 3 & 4 you will see further instructions in the metanodes/sub-workflows (“Encounters” & “Procedures”) that open. Specifically, inside those metanodes, there is a yellow annotation box around the nodes for you to edit that says to “EDIT” the nodes surrounded by the yellow box by “instead of [using] the Table Creator [node inside the yellow box that the workflow currently uses as an example], use File or DB Reader [nodes] to read in your data [in the same format as that Table Creator node]”
What it should also have said to be completely clear is that the Table Creator node above the yellow box specifies exactly what the “Data columns & types for query to return [should be]”, and for the “Encounters” metanode, 2 more Table Creator nodes (also above the yellow box) specify what the “expected encounter types” and “expected encounter specialties” need to be.
Please let me know if anyone is still not clear on this.
Jen
further clarification on data input
answers to few more good Qs from UW:
• Do you have a preference whether we use department specialty or provider specialty to populate this field?
No, whichever is easier, I think I used dept. as that’s easier for us
• In our data, ‘ENT’ denotes Otolaryngology which is a distinct category in the specifications. Is ENT meant to capture something distinct from Otolaryngology?
No, we were just trying to capture all possible names for the specialties we wanted
• Does “OTHER” include anything that is *not* ENT, Allergy, Immuno, Otolaryng?
Yes.
Codes for aspirin sensitivity
Which code(s), specifically, should be used for aspirin sensitivity? I see two codes (V14*,Z88*) in the "Allergies list" related to medicinal agents but none specific to aspirin. Please advise. Thank you!