Migraine is the most common recurrent headache syndrome in children in which 4-10% of school age children may be affected (1). It is characterized by episodes of headache pain that may be accompanied by nausea, vomiting, and light and sound sensitivity. Migraine occurs at all ages and may even begin in infancy as represented by intermittent colic (1). The genes for familial hemiplegic migraine have been identified. For migraine without aura and migraine with aura population and twin studies have been consistent with the genetic basis of migraine, but no consistent genetic etiology has been established. Both genetic and environmental factors are important (2). The International Classification of Headache Disorders 3rd edition (ICHD-3) is the current gold standard for the diagnosis of migraine, especially for research purposes. ICHD-3 notes that certain features of migraine in children may differ from typical features in adults for example it is often bilateral in children, and unilateral pain usually emerges in late adolescence or early adulthood and childhood migraines may be shorter in duration. ICHD-3 criteria require at least five attacks to fulfill the diagnosis of migraine.
Migraine algorithm does not exclude adults. (June 2017)
{kind=link}
Comments
Migraine classification
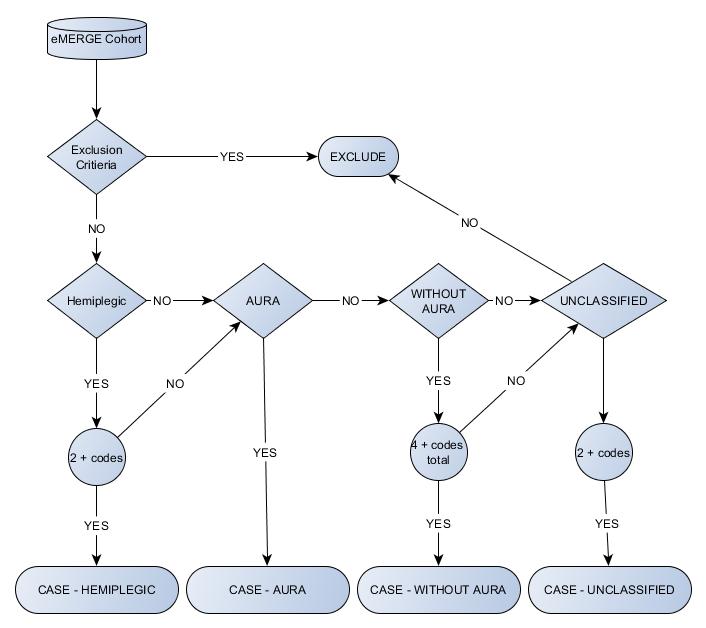
A little confused on the phenotype documentation from Migraine in children_06212017.docx. Cases could qualify under more than one category (Unclassified, Without aura, and With aura). So should case type be determined as follows:
If >= 2 unclassified codes, then consider unclassified.
If >= 4 without aura codes (346.1, 346.11, 346.12, 346.13, 346.7x, G43.0x) then consider without aura.
If >=1 with aura codes (346.0, 346.01, 346.02, 346.03, 346.5x, 346.6x, G43.1x) then consider with aura.
So if someone qualifies under both unclassified and with aura you would consider them as a "with aura" case type?
Also showing the unclassified codes (346.2x, 346.8x, 346.9x, G43.8x, G43.9x) under all three case types. Should these just be under the Unclassfied case type?
Clarification
Here is the proper order to consider the algorithm. Note, these steps are after exclusions.
1. If patient only has 'unclassified' codes (at least 2), then case is unclassfied.
2. else if patient has 'without aura' codes (and 0 'aura' codes), case is 'without aura'.
Count of 'without aura' + 'unclassified' >= 4.
3. else if Patient has aura codes (>=1), case is 'aura'.
For #2 and #3, the patient must have at least 1 of the relevant code. But the definition can use 'unclassified' codes to contribute to the minimum number of codes for 'without aura'.
'Clarification' does not match flowchart nor the text
I'm verifying that we are applying the correct logic as we realized it is stated differently here in the above comment,
and in the flowchart (and not stated at all in the text of the algorithm doc), so our question is:
Is the logic to be applied in the order in the comment above,
& if we are to follow the comment above, where does Hemiplegic fall into that order (it is not listed in the comment)?
And if not, what is the correct logical flow then?
The flowchart shows that the order in which to look for codes is:
If no case exclusions, then :
1) if w/ 2+ Hemiplegic codes & verified w/ manual chart review, then Hemiplegic.
2) else if not hemiplegic, if w/ an aura code, then w/ aura
3) else if not w/ aura, w/ 4+ "w/o aura" codes, then "w/o aura"
4) else if not w/o aura, & has 2+ "unclassified" codes, then unclassified
Also, the text in the document w/ the flowchart does not really specify an order
& also has some conflicting info. (ex., says can inc. unclassified for w/ aura, which doesn't make sense).
Thanks, Jen
FLOWCHART combines text of Hemi and Aura/Without Aura algo
Use Flowhcart to decide between HEMI and NON-HEMI (Aura/without aura) defintions as a starting point.
Without Aura requires 4+ codes. One of these could be unclassified.
logic
ok, then we'll start the logic workflow by looking for hemiplegic, & thus the order to apply the rules would be as follows, correct?
1) if w/ 2+ Hemiplegic codes & verified w/ manual chart review, then Hemiplegic.
2) else if not hemiplegic, if w/ an aura code, then w/ aura
3) else if not w/ aura, w/ 4+ "w/o aura" codes (1 of which can be an enc. w/ an unclassified code), then "w/o aura"
4) else if not w/o aura, & has 2+ "unclassified" codes, then unclassified
Validation of algorithm in adults
Hi,
Has this algorithm been validated in a cohort of adult patients? Will it be? If validation is planned, we would prefer to delay implementation until adult validation is complete because of the possibility that the algorithm will need to be altered, and if altered sites implementing in adult populations prior to its alteration would need to redo their implementations.
Does this seem reasonable?
-David
That is reasonable. Geisinger
That is reasonable. Geisinger validated their Adult cases. The PPV was 96%.
Thanks. We'll proceed. David
Thanks. We'll proceed.
David
Update pseudo code?
Can you please update the pseudo code with the important qualifications posted here in response to questions from implementing sites?
Thanks,
David
Which part do you mean, David
Which part do you mean, David?
The flowchart should be current.
# of attacks req for "Migr w/out aura", def of distinct episode
i see in text of algorithm document "At least five attacks" but see "4 + codes total" in flow document.
in defining "distinct episode", do you require a particuluar number of days between diagnoses, or is it simply "on a different day"?
thanks!
distinct episode
Distinct episode is different day. One can use a different date or encounter id to make the distinction.
The text at the beginning of the document describes clinical definitions. The Case definitions are the full and complete algorithm, with the flowchart aiding in process.
Keep in mind that a patient
Keep in mind that a patient may have >1 encounter IDs on the same date, so "different dates" and "different encounter IDs" mean different things.
David
pls confirm meaning of "codes in distinct encounters"
to verify, we are interpreting, based on the above comments & what other algs. have done,
that the requirement of ">= X" or "X+" # of "codes in distinct encounters" means:
patient has ANY of the specified codes in the given category on >= X # of distinct DAYS,
in order to fall into the given category.
Can you please confirm that this is the correct interpretation?
Please keep in mind that an inpatient encounter can span multiple days,
I believe that was the point David was trying to make.
Thanks! Jen
We implemented it as distinct
We implemented it as distinct episode = distinct encounter.
count = count of distinct enc. (not distinct codes)?
Ok, thanks, then we'll count distinct encounters, not dates, but my other question still remains:
count = count of distinct encounters
NOT count of distinct ICD diagnosis codes
correct?
Thanks, Jen
case ICD10 codes G43.A*, G43.B*, G43.C*, G43.D*
i don't see these included in any of the case sub-groups - are we pulling these for any particular reason?
thanks!
Wide group
Apparently the intent was to get a wide group of patients first, and then narrow by subtype. These codes don't have to figure into the case definitions. Sorry for the confusion.